Elasticsearch
- 搜索引擎
数据库不适合 ,模糊搜索 ,和大量数据的搜索
安装
单机版本elasticsearch , 版本为7.12.1。 注意网络名需要修改 !
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network heima \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
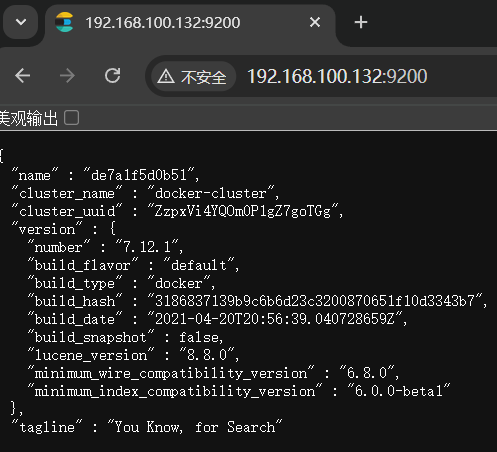
访问9200端口
安装Kibanna , 还是注意网络名
- -e 指定的是 elasticsearch的端口地址
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=heima \
-p 5601:5601 \
kibana:7.12.1

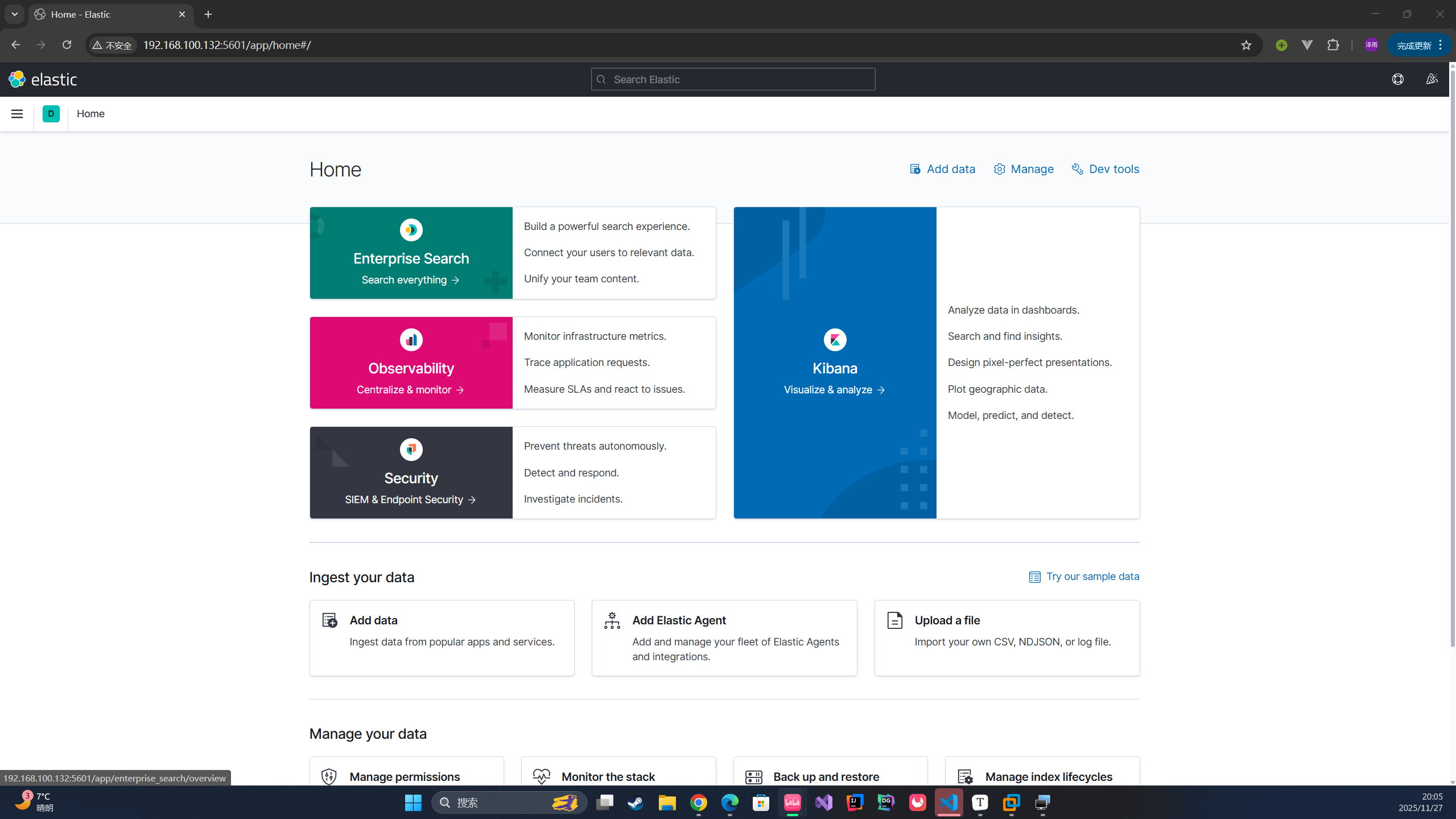
访问5601端口
虚拟机内存需要大一点 , Elasticsearch需要的内存比较大
DevTools
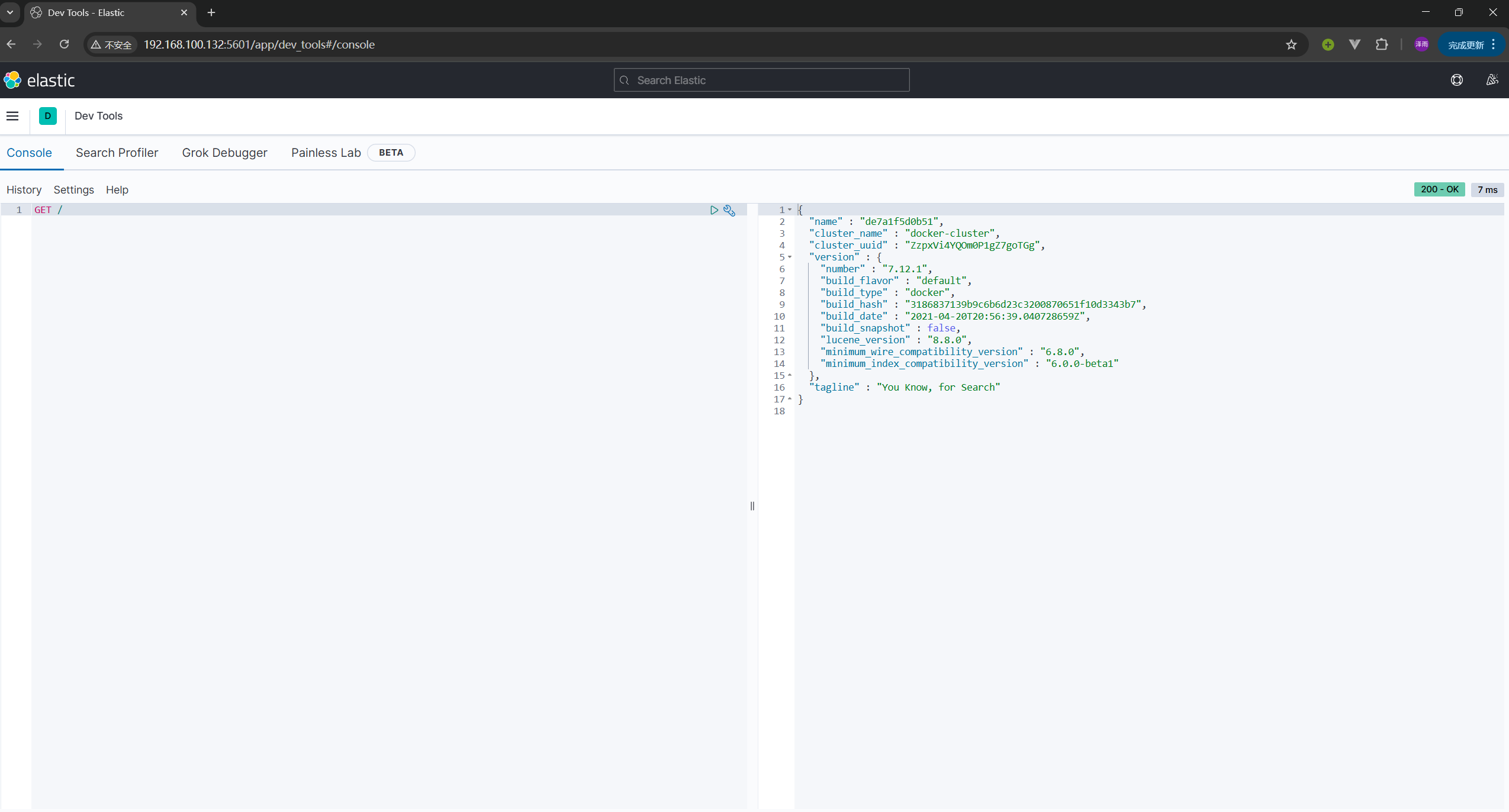
使用kibanna 发送请求 , / 为原本的地址(因为kibanna在创建时就知道elasticsearch的地址 , 直接访问 / 就是192.168.100.132:9200)
倒排索引
MySQL 为正向索引 , 采用B+树 找到叶子节点查询数据
如果是模糊搜索 , MySQL为逐行搜索。
- 文档:每条数据就是文档
- 词条: 文档按照语义分为词语
根据词条索引查询
IK分词器
- 英文会用空格分词 ,中文分词比较麻烦
安装
挂载插件挂载到指定目录即可
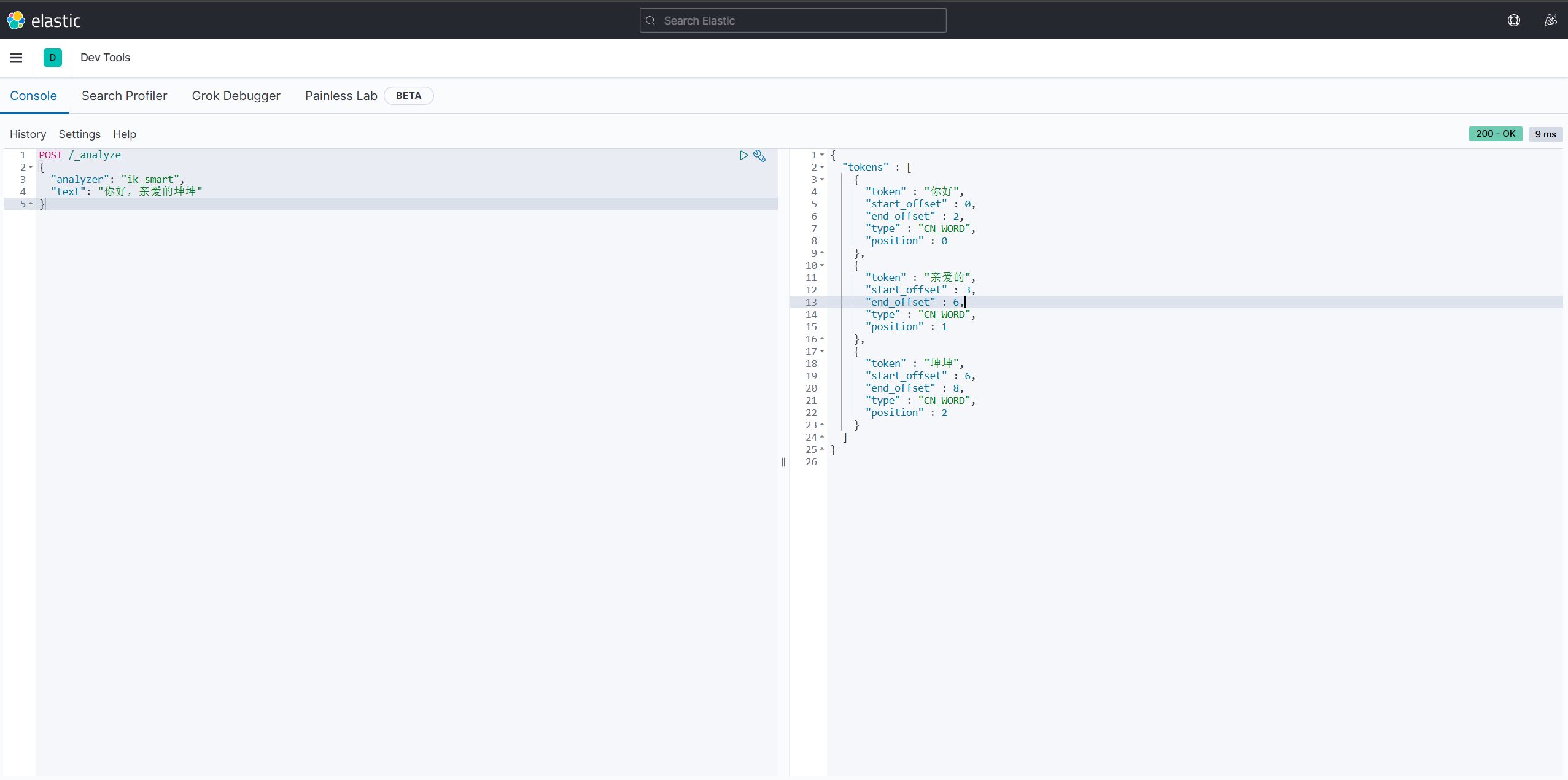
测试分词器
使用Kibana发送请求
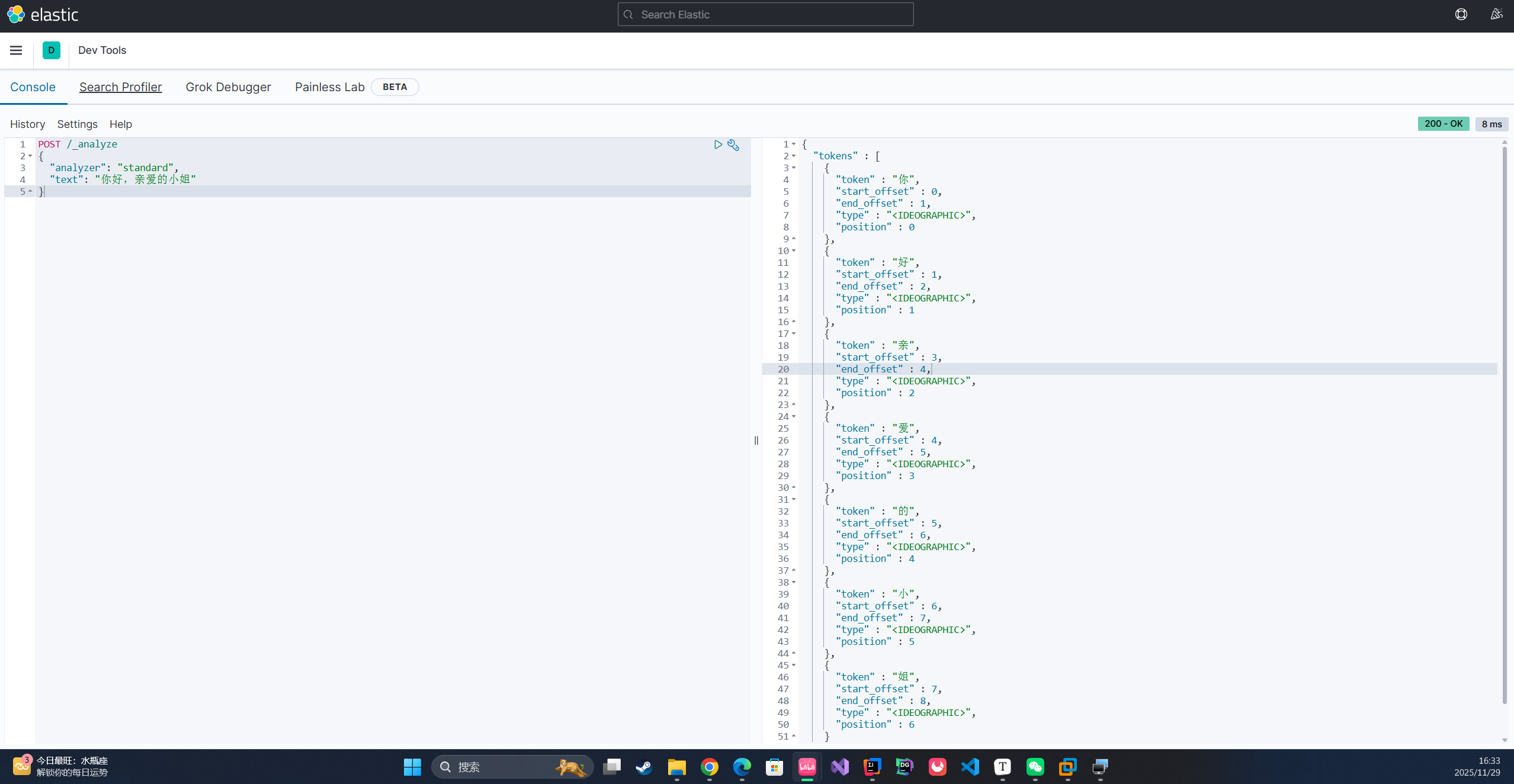
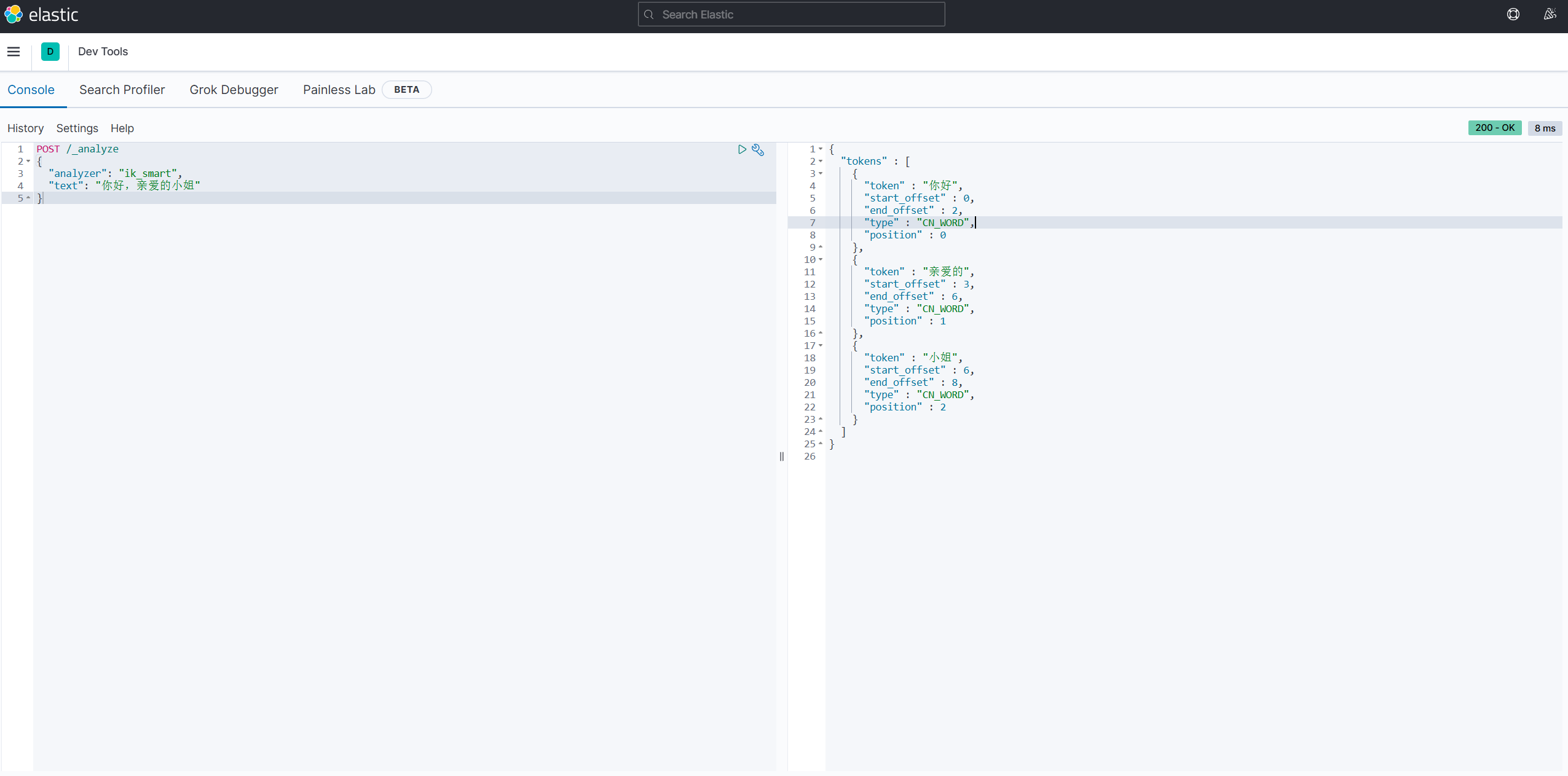
标准分词器将中文一个一个分开 ,IK分词器可以按照自己的词典将每个词分出来
新产生的网络词语 ,等不会自动分词, 需要自己添加词典 , 在IK分词器xml配置文件中指定自己的词典, 把词典加入Config中
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
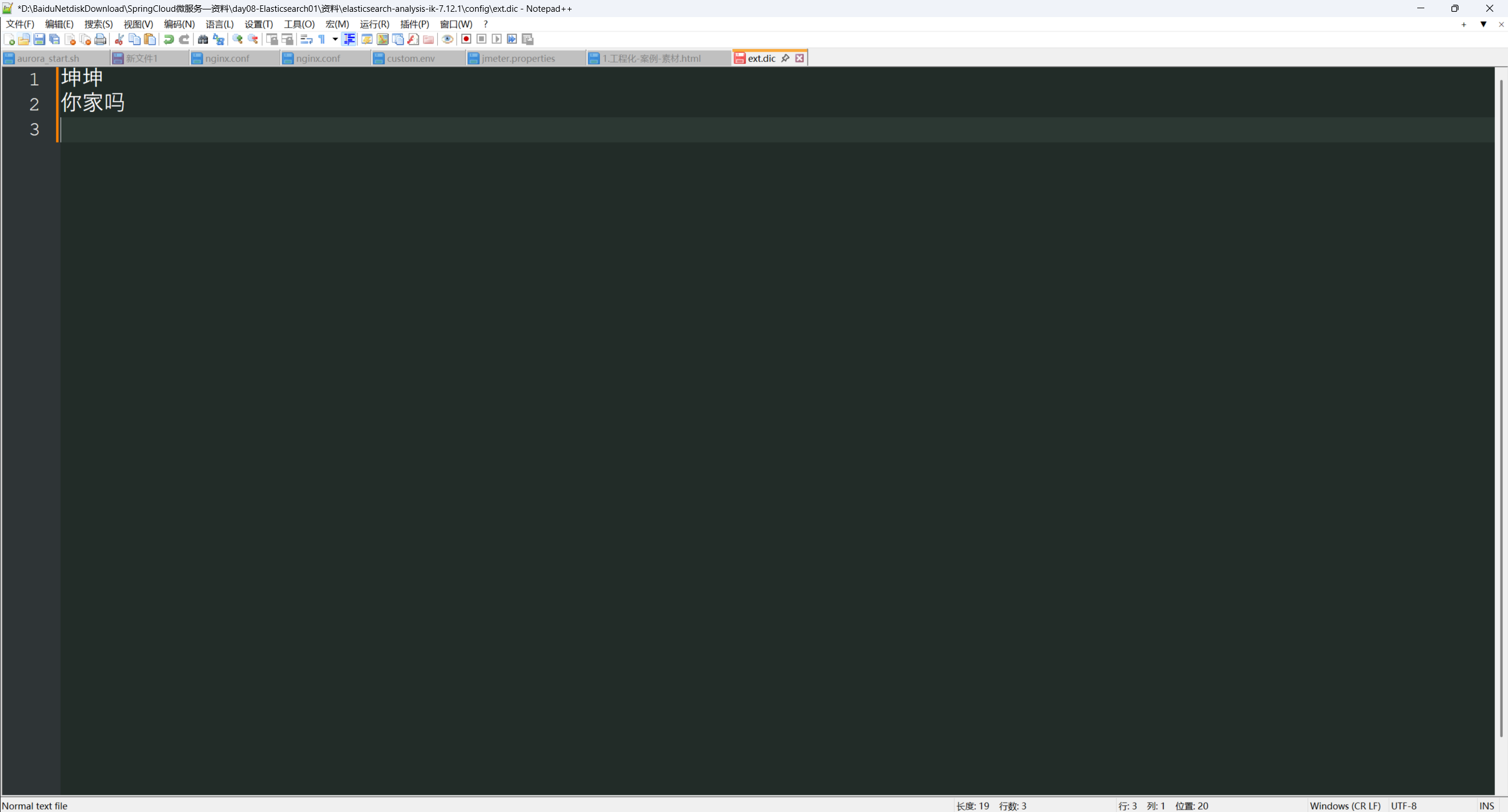
直接添加自己的词典就可以 , 还有停止词典,可放入语气词,禁止词等